
By Mrinal Sarkar, Sr. Solution Architect, Dasher Technologies
These days it’s hard to imagine any Tech Forum or News site not talking about Big Data. I’m sure you have heard it too but have probably been puzzled by the numerous definitions and interpretations. In this discussion we will try to make some sense of the plethora of Big Data technologies out there and simplify it to a discussion on a few prominent ones in this space.
Big Data is the term for a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications. The challenges include capture, curation, storage, search, sharing, transfer, analysis and visualization.
Consider the example in the picture below. US commercial jets create about 1 Zettabyte of data per year. In fact, almost every business and technology discussion these days start with statements about the explosion of data that surrounds us, and often threatens to overwhelm us.
 While the term Big Data may seem to reference the volume of data, that isn’t always the case. The term Big Data, may refer to the complicated infrastructure that an organization must invest in to support Big Data. The term Big Data is believed to have originated within Web search companies who had to query very large distributed aggregations of loosely-structured data. Traditional Data processing (i.e. Data warehouse or Decision Support Systems) were built for a different set of requirements where the data is highly relational, structured and rarely goes into the realm of more than a few hundred terabytes.
While the term Big Data may seem to reference the volume of data, that isn’t always the case. The term Big Data, may refer to the complicated infrastructure that an organization must invest in to support Big Data. The term Big Data is believed to have originated within Web search companies who had to query very large distributed aggregations of loosely-structured data. Traditional Data processing (i.e. Data warehouse or Decision Support Systems) were built for a different set of requirements where the data is highly relational, structured and rarely goes into the realm of more than a few hundred terabytes.
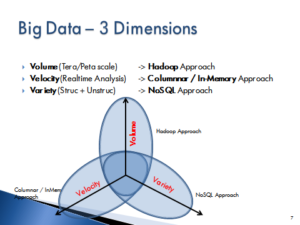
The solutions of the past are not a good fit for the tremendous challenges that come with the new style of data. Big Volume, Variety and Velocity are the challenges of today. Over the years solutions have been designed to answer the requirements of one or more of the V’s.
In this regard the most commonly observed approaches are:
- The Hadoop Approach that addresses the volume and scalability aspect of Big Data
- The No-SQL approach that addresses the variety in structure, format and type of data
- The Columnar/compressed approach that is geared towards the velocity or rapid data processing and analysis needs.
These approaches are not exclusive solutions. A solution that is designed to address high volume and scalability also must address the Variety and Velocity challenges of the data set. But as you see from the diagram below, the solutions typically cover one area more completely and touch on the other V’s.
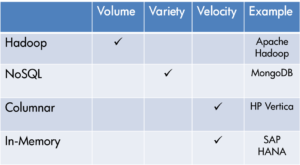
 Here’s a shortlist of the Top three technologies that are used to address the “Big Data Challenge”.
Here’s a shortlist of the Top three technologies that are used to address the “Big Data Challenge”.
Hadoop
 Hadoop isthe crown jewel and darling of Big Data. As an Opensource project that is released under Apache License, it can be used for storage, for transactions, for computations and for analytics. Hadoop deals mainly with Volume (and to a lesser extent Variety) when it comes to Big Data.
Hadoop isthe crown jewel and darling of Big Data. As an Opensource project that is released under Apache License, it can be used for storage, for transactions, for computations and for analytics. Hadoop deals mainly with Volume (and to a lesser extent Variety) when it comes to Big Data.
NoSQL
 Most NoSQL solutions tend to focus on the Variety problem of Big Data. When you hear the phrase NoSQL – it means “Not Only” SQL and there are a variety of technologies in this space.
Most NoSQL solutions tend to focus on the Variety problem of Big Data. When you hear the phrase NoSQL – it means “Not Only” SQL and there are a variety of technologies in this space.
The logos below represent the most common NoSQL solutions in the industry. NoSQL handles BOTH structured and unstructured data.

Columnar Data Stores
These are databases that store data in a columnar fashion, not in a row fashion like traditional databases (Oracle, MS SQL). Traditional databases are used for handling transactions.
Columnar databases are used when you are not interested in an individual or a specific transaction, but rather an aggregation of a field of a specific transaction type. Columnar databases are databases that are designed and built with analytics and reports in mind.
 They are usually proprietary solutions like HP Vertica.
They are usually proprietary solutions like HP Vertica.
HP Vertica deals with Velocity, where the interest is mainly in analytics. In-memory databases also address Velocity.
The idea behind in-memory databases is the trend of shifting data processing from storage and traditional databases into pure memory. This can go from one extreme of simple distributed caching solutions through key-value stores and up to in-memory data bases. These solutions are expensive (memory costs more than disk space), but they are fast. Since memory is volatile, reliability is achieved either by write-behind mechanisms, where data is stored on disk for retrieval in cases of disaster; or simply by replication on multiple machines. SAP HANA is an example of an in-memory database.
 Summary
Summary
There are two things to remember about Big Data:
- Big Data is a moving target – The market of data processing is changing around us.
- There is no silver bullet – As with anything else, there’s no “one-size-fits-all” solution.
Most enterprises end up using multiple Big Data technologies to solve their problems. If you are looking for a solution to a Big Data problem, start by defining which of the Big Data V’s are causing you a headache and move on from there to select the right set of technologies to use. It is likely you’ll end up using more than one!
At Dasher Technologies, we have helped several customers navigate through the maze of Big Data and we would be glad to assist you in your project as well.
Sources of Info:
http://www.gartner.com/technology/topics/big-data.jsp
http://hadoop.apache.org/
http://en.wikipedia.org/wiki/Big_data
http://en.wikipedia.org/wiki/Column-oriented_DBMS
http://www.vertica.com/the-analytics-platform/