
Forward by Chris Saso, CTO & Content and Blog by Isaack Karanja, Senior Solution Architect
For the next installment in our multi-part series on moving from OS virtualization to workload virtualization (containers), we will discuss orchestration engines, scheduling, service discovery, load balancing, Docker Swarm and Kubernetes.
Orchestration Engines
Although you can have multiple applications running in one container, it is generally considered a best practice to have each container manage one application process. This means that you typically have more containers than virtual machines for the same application. The process of provisioning containers can and should be optimized through the use of automation. Container orchestration tools help our clients to answer questions like:
- How do I schedule running containers within available resources (hosts)?
- How do I deal with container failures?
- How do I deal with host failures or host maintenance?
- How do I scale my containerized application up or down?
- How do I deal with application updates?
- How do I deal with security of my application and secure my company IP?
- How do I deal with persistent storage for my containerized applications?
- How do I deal with networking and load balancing?
One thing to note is that container orchestration engines manage the end-to-end lifecycle of your application, all the way from the “developer” when the application is being built and tested, to “operations” where the application is moved into production. There needs to be a collaboration effort between your companies’ developers and operations teams in order to pick an orchestration tool that meets the goals of the business. The following diagram shows the Orchestration Components that I will discuss in more detail in this blog.
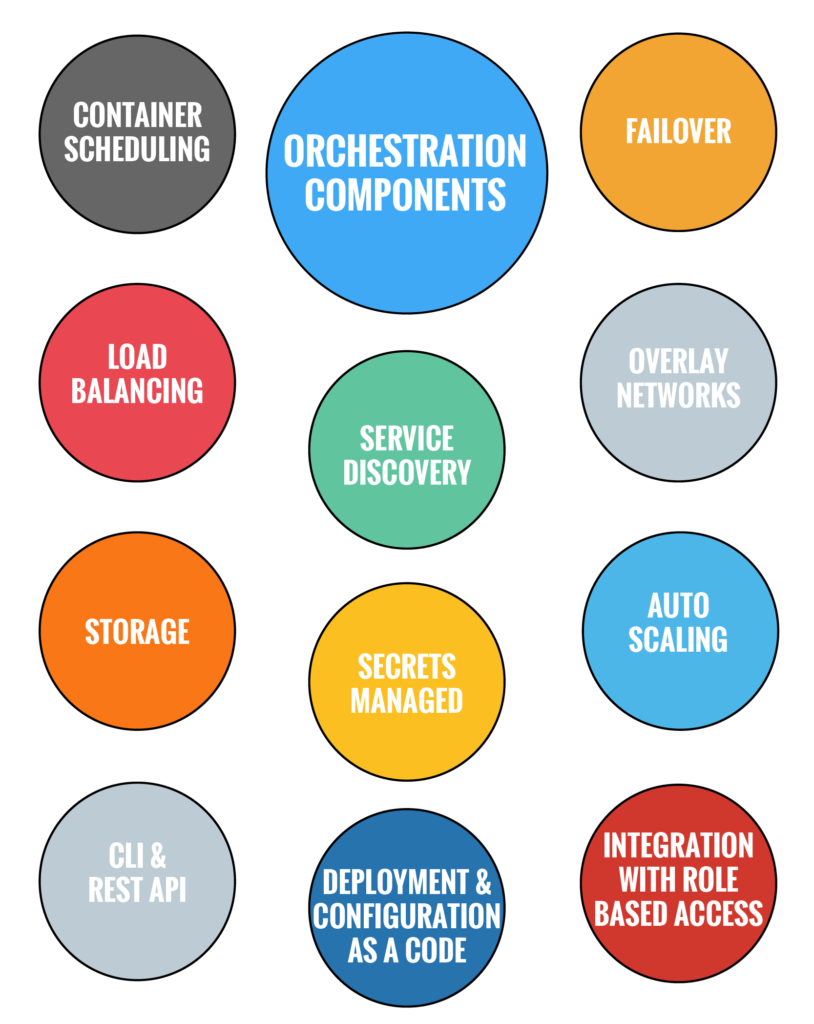
There are several orchestration engines that are available in the market today and this space is evolving rapidly. As a matter of fact Docker just added support for Kubernetes to its platform! Wow!
Some of the leaders in the space are:

I am going to focus on the two most popular container orchestration platforms, Docker Swarm and Kubernetes.
Docker Swarm
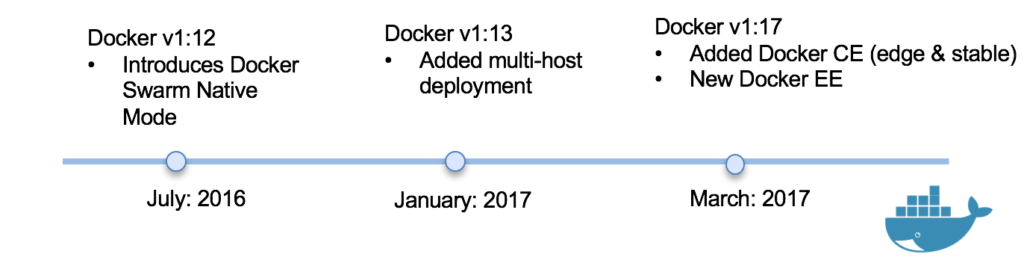
Docker Swarm is the Docker Native Orchestration product. Docker Swarm has evolved rapidly over the last couple of years. Prior to mid 2016, one had to manually install and configure Docker Swarm. In July 2016, Docker released Docker 1.12 which included Docker Swarm Native built in to the Docker Engine. Below is a timeline of some of the major changes added to Docker over the last 18 months:
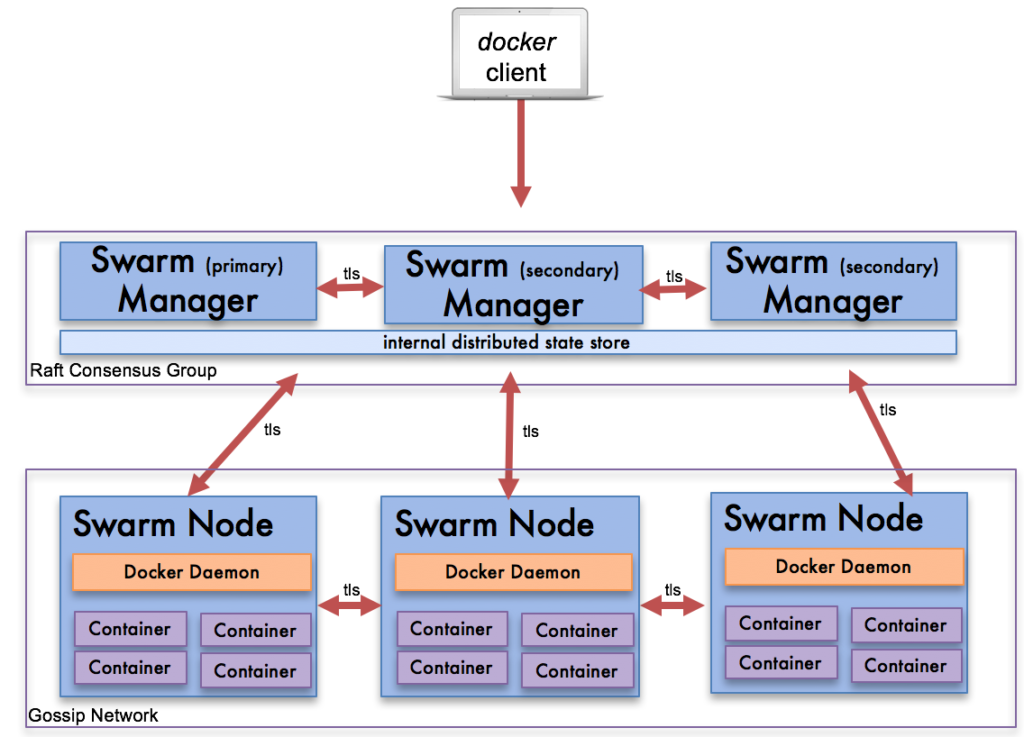
Docker Swarm Architecture
There are very few components to Docker Swarm because most of the components are built into the Docker Daemon running in each host. This makes it very easy to install and configure. To install the cluster, you start by installing the Docker Daemon either on physical or virtual servers. You then install the services necessary to run Docker Swarm which run as containers.
Ease of Use
Docker’s goal is to make containers easy to use. Docker Swarm allows this by borrowing concepts used when running Docker Daemon in a single host. It is very easy for a user familiar with Docker single host to run an application in Docker Swarm. Docker also makes use of YAML files to describe containers and these files have similar format to Docker single host and Docker Swarm.
Docker Swarm Features
Storage
For persistent storage, Docker uses the concept of storage volumes. These volumes can be mapped to any shared or distributed storage. It comes included with the local volume and NFS driver. Docker Swarm allows you to install plugins that allow you to use third party storage systems.
Networking
Each Docker Swarm node comes with an autoconfigured overlay network for container traffic. This allows ingress, egress and inter container communication regardless of node placement on a Swarm cluster. When you deploy a container to any of the Swarm worker nodes, all the worker nodes that are part of the Docker Service respond back with the application port regardless of whether they are running the container or not. They then route the traffic through the “routing-mesh” to the appropriate worker node running the container.
Inter node traffic is auto-configured TLS encryption with mutual authentication to encrypt the data. Docker Swarm is also responsible for key rotation of these TLS certificates. You can use the built in internal certificate or bring in an external certificate.
One thing to note, similar to storage, is the end user has the capability of extending Docker networking capabilities by the use of networking plugins.
Scheduling
In a Swarm, each task maps to one container. When using Docker you can control container placement decisions by using labels (tags) either user defined or system defined. The scheduler also takes into consideration CPU and memory constraints when scheduling containers.
In Docker 1.2, Swarm introduced Docker Service. When using Docker Service, the scheduler continuously monitors the desired state. For example, it can monitor the number of containers running and it takes action when the desired state is in violation, in case of a node failure, restarting containers in another host.
Service Discovery
Service Discovery requires three things. First is some sort of DNS service that allow services to dynamically get IP addresses of each other. Second is a form of health check to ensure that only healthy instances get traffic, and third is load balancing to ensure all containers running a particular application get traffic routed to them.
In Docker Swarm, service discovery is handed by internal DNS components that assign each service a virtual IP and DNS entry in the Swarm overlay network. The DNS entries are maintained in the Docker Engine. Containers share DNS mappings via an internal gossip network and any container can access any other service by referencing its service DNS name. Docker swarm utilizes a custom instruction to check whether the container is healthy. Load balancing is handled by the Docker Swarm network mesh.
Load Balancing
As of Docker 1.2, when you deploy a service, it gets a virtual IP and DNS entry and load balancing is automatically handled by the Docker engine through IP Virtual Server (IPVS). When that service is requested through DNS, Docker services that request through the IPVS and routes the traffic to all the healthy containers. The user is not required to implement any load balancing but can use an external load balancer to distribute traffic across the nodes.
Docker Editions
Everything we just described is part of the Docker Community Edition and Enterprise Edition.
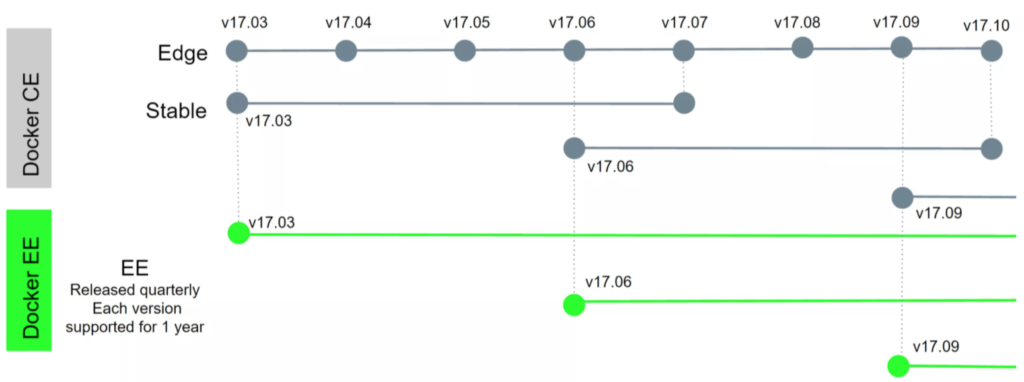
Docker Community Edition
- Stable (Quarterly releases) – this has feature parity to the enterprise edition
- Edge (Monthly release) – this is has all the latest features
Docker Enterprise Edition
For the enterprise customer, Docker recommends that you use Docker Enterprise Edition. Docker Enterprise has two main features:
- It is based off the quarterly stable release of Docker Engine
- It adds enterprise features to Docker Swarm by adding on the Universal Control Plane (UCP) on top of Docker Swarm.
- It comes with an enterprise support contract of either next business day or 24/7 support
Here are some of the features in Docker Enterprise Edition:
- Web UI – UCP adds a web interface to Docker Swarm for monitoring and configuration
- Monitoring and Log Aggregator – UCP includes real-time monitoring of the cluster state, real-time metrics and logs for each container.
- Docker Trusted Registry – Docker Enterprise includes a container image solution that can be deployed on-prem or private cloud. DTR can use storage from local disk or object storage.
- Docker EE Security
- Image Signing
- Specify groups users/groups that can sign secretes
- Ensure that only signed containers run on Docker Swarm
- Container Scanning
- Integrates with Docker SaaS service where it scans Docker images for known security vulnerabilities when they get pushed to the Docker Registry
- Role based access with built in authentication modules
- You can tag containers and specify RBAC controls for networks and containers
- Enforces least privilege access model
- Secrets Management
- Provides built in secrets management
- Only master nodes have access to secrets database
- To grant running containers access to secrets, secret files are automatically mounted to container memory
- Image Signing
Docker Summary
In keeping with the mantra: build, ship, run anywhere, Docker has made it easy for the development team to containerize their applications and for the operations team to deploy Docker Swarm in production. Most of the tools that developers use when running Docker in standalone mode are very similar to the tools used to manage the application in production. If you add on the Docker Enterprise features, Docker Enterprise becomes the logical choice for enterprise customers who want to get containers running in production in an all-in-one orchestration framework that has a short learning curve. Although Docker Swarm still lacks some of the more advanced Kubernetes features, it has done a lot of growing up over the last 18 months and has added features. For example it has added services that have made it a serious contender in the container orchestration platform ecosystem.
Kubernetes
Kubernetes was born out of the Google Borg system that Google had been using to manage their containerized applications for over a decade. Google released Kubernetes as an open source project in 2015. Since the Kubernetes project was based off Borg, it was already field proven to be able to run large scale production workloads. In 2015 it became an open source project under the Cloud Native Computing Foundation (CNCF). Kubernetes is container engine agnostic. It will run Docker containers, Rkt containers or even LXC containers.
As of October 2017, it is considered the most viable alternative to Docker Swarm in Docker CE & Docker EE and as noted above is now supported by Docker.
Kubernetes Architecture
Kubernetes is a lot more complicated, and more powerful, than Docker since it has more components to install. It is similar to Docker in that it has a master node and worker nodes. All of the Kubernetes components can run in Docker so you would start your Kubernetes install with a clean install of a Docker Engine. However, unlike Docker Swarm which is very opinionated with its install, there is a multitude of options on how to deploy Kubernetes. Solutions range from, private cloud, bare-metal based installations, VM-based solutions, using cloud providers, open source configuration management tools all with different networking, storage and load balancing options. This has made evaluating Kubernetes difficult and given it a reputation of having a steep learning curve.
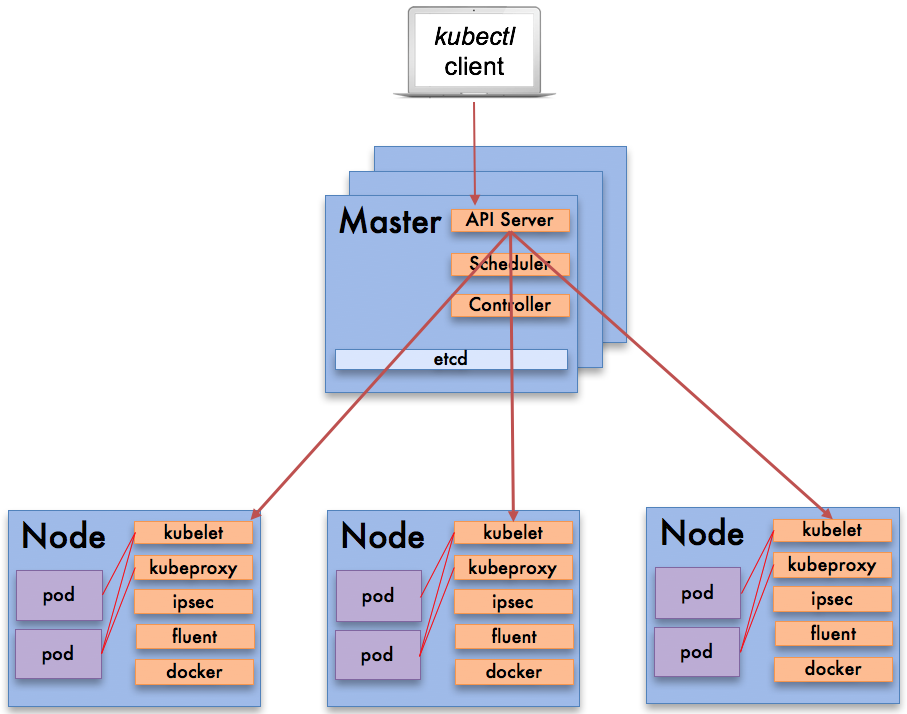
Ease of Use
Kubernetes has the equivalent of the Docker command line, kubectl. It also has its own version of the YAML files to describe containers and services. Kubernetes uses the concept of pods to represent what Docker Swarm calls containers. Kubernetes pods are one or more containers that reside in a single host.
One thing to note, for a user coming from Docker and its ecosystem is that Kubernetes introduces new concepts that at first might seem confusing. However, once understood, these concepts allow Kubernetes to have a more powerful management model as compared to Docker Swarm. When describing applications, Kubernetes tends to be more verbose than Docker Swarm just because of available knobs that you can adjust.
Kubernetes Features
Storage
Like Docker Swarm, for persistent storage, Kubernetes uses a concept similar to what you get with Docker volume plugins, only with more capabilities. One of the main limitations with Docker plugins is that you can have only one volume plugin per container. Kubernetes lets you use multiple volumes per container. Kubernetes supports different volume types just like Docker.
One other major difference between Kubernetes and Docker is that Kubernetes volumes are built outside the definition of the container. This means that by design, the lifecycle of the container is independent of the lifecycle of the container (pod) and is meant to outlive the container.
Networking
Both Kubernetes and Docker Swarm require overlay networks for containers that are on different hosts to communicate with each other. The overlay network is built into the Docker Swarm deployment using sophisticated “mesh” network. Kubernetes, on the other hand, implements a flat networking model where there is no native implementation of overlay networks. Kubernetes supports CNI (Container Network Interface Standard), a plugin architecture that allows you to use third party solutions. This includes:
-
-
- Flannel – Simple overlay network that meets basic Kubernetes requirements
- Contrail/OpenContrail – Juniper Networks and its open source SDN offering
- VMware NSX – VMware SDN offering
- Contiv – Open source project
-
Another major difference is that all containers in a Kubernetes pod (which can be composed of multiple containers) share a common IP address, which means they need to coordinate port usage. IP addresses for pods and services by default are only exposed internally within a Kubernetes cluster. In order to expose an IP address externally, you need to create a Kubernetes ingress resource.
Scheduling
Kubernetes has rich scheduling functionality when compared with Docker Swarm. Docker Swarm and the end user have the capability of swapping out the scheduler. Kubernetes can use the following scheduling options:
-
-
- Replica Sets: Is a scheduling option that ensures that a specified number of pod replicas are running at any given time.
- Deployments: This is a high order scheduling option that is used to control replica sets and pods. It is declarative where the user specifies what they want to accomplish and Kubernetes makes it happen. When you use deployments, you don’t have to manually create replica sets. Deployments automatically manage their creation. Deployments allow you to create new replica sets, rollback, scale up, pause a deployment and clean up older replica sets.
- Stateful Sets: This is a scheduling option specifically designed for use with containers that are considered “Pets”. For example, containers that have requirements such as stable network identifiers, stable storage, specific control in shutdown or scaling.
- Daemonsets: This is a scheduling option specifically to ensure that containers run on all the Kubernetes nodes.
- Cron Jobs: This is a scheduling option for running containers that need to be run at a certain time of day.
-
Load Balancing
In Docker Swarm, all container load balancing is implemented within the internal “mesh” network. Any load balancing is used to just front-end the Docker worker hosts. Kubernetes on the other hand, provides you two different options:
The first option is to use the “load balancer” resource which creates a load balancer in GCE, AWS or any supported cloud provider.
The second option is to use a combination of the “Ingress Resource” (collection of rules to reach cluster services) and the Ingress Controller Resource (a HAProxy, Vulcan or Nginx pod). The way this works is that the Ingress Controller Resource receives its configuration information from the Ingres Resource and provides load balancing to the service that front ends the application pod (Nginx Pod –> Ingress –> Service –> Application Pod).
Service Discovery
In Kubernetes, a key value store eg “etcd” is used to maintain IP to service name mappings. Kubernetes maintains an internal DNS service for internal services. Health checks are handled by a process on each Kubernetes node. For health checks, the Kubernetes users have two options: liveness (whether the app is responsive) and readiness (if the app is still preparing but not yet ready to serve traffic). A Kubernetes user can also specify a custom health check using exec probe. Kubernetes can integrate with an external DNS service allowing it to create DNS records when services are created. Load balancing is accomplished either using load balancer or Ingress resources.
Autoscaling
Docker Swarm only allows manual scaling of services. Kubernetes allows auto-scaling based on response to application demand.
Helm Charts
Because of the complexity describing containerized applications in Kubernetes, Kubernetes introduced a Kubernetes based package manager called Helm Charts. Kubernetes Helm Charts are a sharable and distributable description of containerized applications written using best practices ready to be installed in a Kubernetes environment. Helm Charts are currently the most active project within the CNCF and makes it easy to download and install containerised applications in Kubernetes.
Kubernetes Summary
Kubernetes is definitely not as easy to install and get into production as Docker Swarm. However, it does provide a more expansive feature set. There are more scale-out deployments for Kubernetes and as an orchestration engine, Kubernetes receives broader support from the open source community than Docker Swarm. Similar to the Openstack foundation, there are also many Kubernetes distributions and the user has many options to deploy Kubernetes.
The flexibility and options of Kubernetes also contribute to its complexity and thus maybe to its disadvantages. For example, Kubernetes supports advanced use cases like setting quotas for CPU, memory and storage on multi-tenant environments limiting the tenants to a fixed number of users. Outside of investing in a supported container distribution, and without a lot of investigation and trial and error it is difficult for the new user to determine the best practices for deploying Kubernetes.
Wrapping it all up
In our Silicon Valley demo lab we have created Docker Swarm and Kubernetes environments to help us learn and demonstrate the pros and cons of each solution. If you would like to learn more about containers and workload virtualization please drop me a line and let’s talk about it!